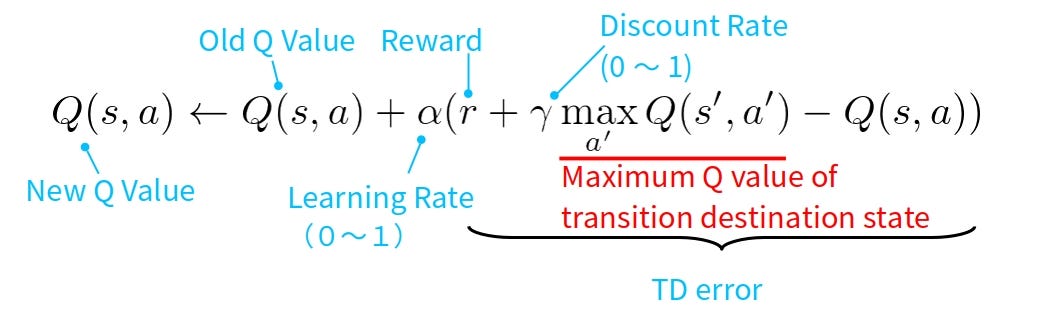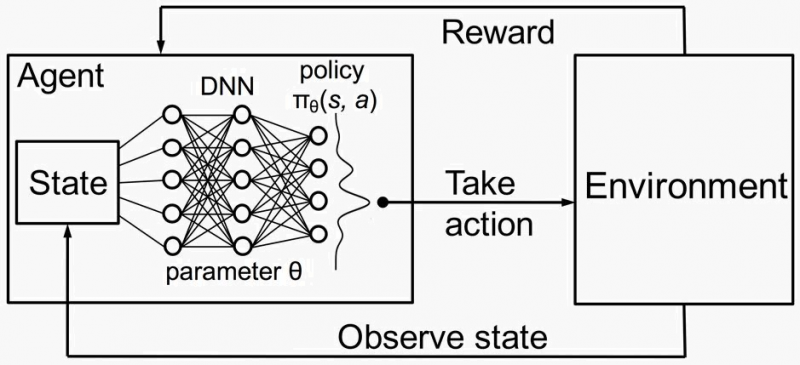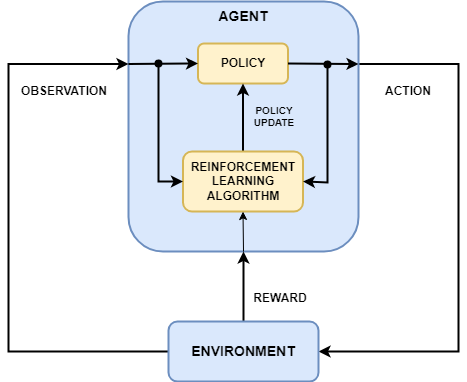


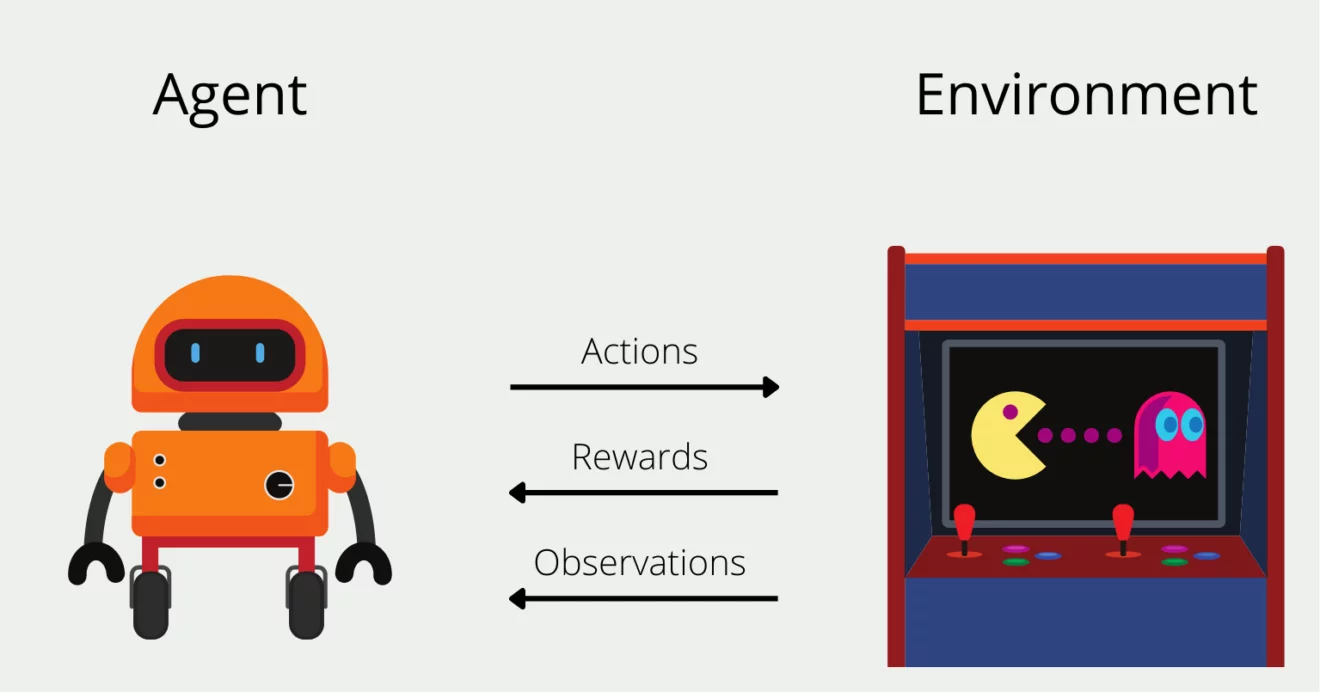
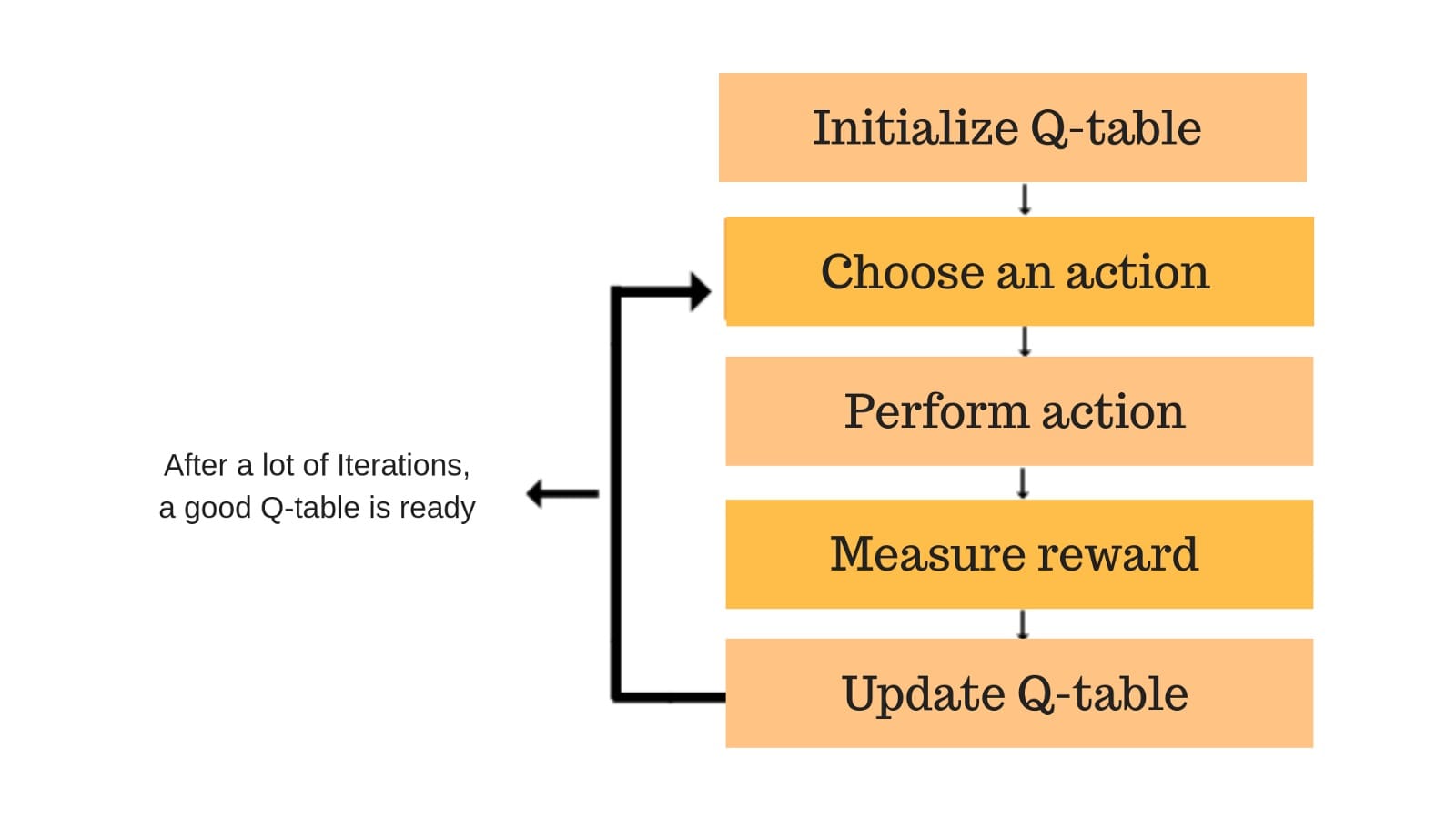
Q-learning is a model-free reinforcement learning algorithm that enables an agent to learn an optimal policy for decision-making. It works by estimating the Q-values (action-value function), which represent the expected cumulative reward for taking an action in a given state and following the best future actions. The agent updates Q-values iteratively using the formula: